





: AI sovrana sprona le aziende")


: Nuova sede, stessa strategia")











: Business AI, cambia il fare impresa")














Dopo anni passati ad occuparsi del software e delle relative architetture software che hanno portato a una significativa stratificazione di livelli, qualcuno si è accorto che senza dati si fa poco, cioè che non sono sufficienti funzionalità e potenza di calcolo, se mancano un’intelligenza, le competenze e soprattutto se le informazioni da elaborare non sono qualitativamente all’altezza.
In parole più semplici, non solo si fa poco, ma lo si fa anche male se i dati sono: di cattiva qualità, incomprensibili, inaccurati, ridondanti, falsi e non in linea con la dimensione temporale.
Se i sistemi gestionali in qualche modo aiutano a superare il problema, la situazione è drammatica in ambito Business Intelligence e Analytics ove dati interni ed esterni convivono spesso senza regole precise. Il problema non è sfuggito agli informatici.
Data Quality e Master Data Management
Ci si è dilettati con la Data Quality alla ricerca della qualità e ci si è provato con il Master Data Management (MDM), ovvero la ricerca della verità unica come antidoto ai dati duplicati che raccontano una medesima evidenza ma in modo differente.
In ambito Data Quality si è lavorato parecchio e un po’ di risultati si sono ottenuti: c’è una certa consapevolezza. Il problema relativo a Master Data Management si è rivelato più arduo da risolvere poiché le applicazioni evolvono e crescono velocemente con i dati e potrebbe sembrare di sparare ad un bersaglio in movimento. Non solo, i dati sono in drammatico aumento in quantità e in varietà.
Rimuovere duplicati, standardizzare i dati, incorprorare le regole per eliminare i dati errati, all’ingresso nel sistema sono criticità che si legano anche alle segmentazione delle business unit e delle linee prodotto. Qui si genera una pericolosa ridondanza dei dati aggravata dai cicli di vita di front-to-back office.
Tanti e subito, quale valore?
L’esplosione della quantità dei dati, il fenomeno social, il cloud sono ben noti a tutti noi: quantità enormi di dati si muovono in continuazione ed è facile perderne il controllo.
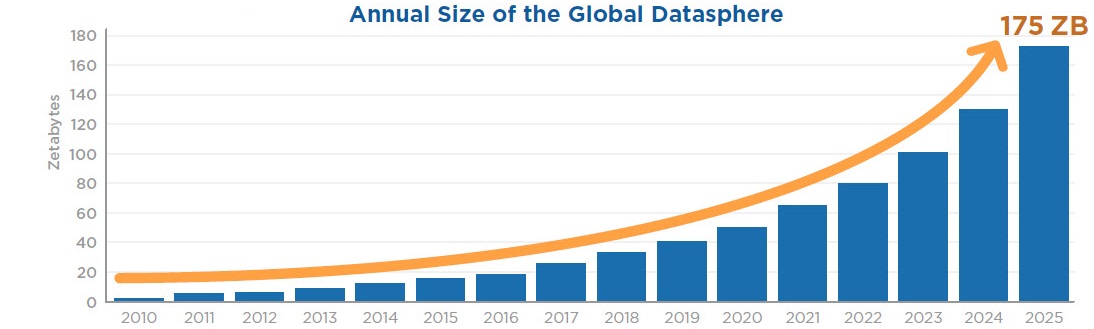
Le previsioni di IDC raccontano che la sfera dei dati a livello globale aumenterà fino a 163 miliardi di ZB (lo zettabyte equivale a un trilione di gigabyte) entro il 2025. Significa un incremento fino a 16 volte rispetto a solo due anni fa, ed è una crescita che impressiona se si pensa che nel 1986 questa sfera era grande appena 281 PB (con il petabyte che è una milionesima parte dello ZB).
A fronte di quantità impressionanti, quello che spesso gli informatici non hanno mai tenuto in considerazione è il valore dei dati. Quanto vale un dato? Qual è la catena del valore di un dato? E’ un valore che può essere messo a bilancio?
A queste domande non è banale rispondere, si può stimare il valore di un dato partendo dal prezzo che si pagherebbe per comprarlo dall’esterno più i costi di trasformazione e gestione. Dato che non è un calcolo banale, si preferisce classificare i dati secondo le regole proposte dalle normative. E visto che parliamo di normative, entriamo in un altro campo che gli informatici non hanno mai preso in considerazione, l’aspetto legale.
Sul versante legale ci si può chiedere, per esempio, che cosa accade se le informazioni vengono copiate o si rovinano, oppure quali siano le normative a cui debbo adempiere per garantire i diritti degli stakeholder.
Ne consegue un ragionamento specifico ovvero: quali sono i rischi che corro se non metto a punto una strategia sugli economics e legale sui dati? Anche qui non sono gli informatici a fare dottrina, ma gli altri stakeholder, chi possiede i dati.
I dati non appartengono agli informatici
Gli informatici si sono sempre posti pochi problemi sui dati anche se una volta si cercava almeno di progettare i database con criterio. Per anni i buoni progettisti sono stati cacciati nelle catacombe in nome della libertà applicativa con i problemi conseguenti di cui sopra: i dati non sono degli informatici ma hanno dei responsabili, spesso responsabilità legali ed aziendali (rispetto delle Normative e dei livelli strategici di business). Un esempio su tutti: il regolamento GDPR.
La Data Governance (DG) nasce per rispondere a questa esigenza: un insieme di regole, processi, organizzazione, ruoli e (pochi) strumenti per formalizzare, misurare e migliorare tutte le attività afferenti ai dati.
La Data Governance coinvolge quindi molte persone di differenti culture ed estrazioni professionali per raggiungere lo scopo. Un programma di Data Governance non è un impianto burocratico ma è un programma di cambiamento culturale che ha obiettivi strategici ed operativi e che non ha un termine poiché segue l’evoluzione dell’azienda.
Si tratta di navigare fra due sponde perigliose: la cattedrale impossibile da mantenere nel tempo e calata dall’alto e la soluzione di facciata qual tanto che aiuti a passare la nottata. In entrambi i casi tutto resterà come prima.
E quindi torniamo alla domanda del titolo: fare Data Governance non è una questione burocratica, ma di governo agile. Serve stabilire poche regole, serve avviare un programma basato sul raggiungimento nel tempo di obiettivi sostenibili e misurabili (di processo, organizzativi, legali, tecnologici etc.) che siano condivisi con gli stakeholder.
© RIPRODUZIONE RISERVATA


: AI sovrana sprona le aziende")




")