





: AI sovrana sprona le aziende")


: Nuova sede, stessa strategia")











: Business AI, cambia il fare impresa")














Ricercatori ed esperti concordano nell’immaginare per il futuro molteplici piattaforme di calcolo basate su tecnologie anche molto differenti tra loro, a seconda degli obiettivi di ricerca. Tra dieci anni, per dire, non si penserà più al computing facendo riferimento esclusivamente a pc, server e data center con processori al silicio, come oggi, quanto piuttosto a specifici sistemi di calcolo specializzati nell’indirizzare altrettanto specifiche esigenze. In diversi contributi abbiamo già accennato al futuro del quantum computing, in questo contesto invece ci preme lanciare alcuni spunti di riflessione specifici relativi al biocomputing, per familiarizzare con tecnologie, di cui ancora oggi si sente parlare relativamente poco, che per il mercato però sono già in pieno sviluppo (tra queste, solo per un ulteriore esempio anche il carbon-nanotube computing). Per gli analisti si parla di un mercato, quello del biocomputing, che valeva poco più di 5 miliardi di dollari nel 2023, ma che almeno fino al 2033 è destinato a crescere per superare i 40 miliardi di dollari (fonte: Straits Research) ed è indicato da Gartner tra i trend tech emergenti per il 2025.
Biocomputing, il calcolo basato sulla biochimica
Il biocomputing, noto anche come calcolo biologico, rappresenta un campo di ricerca emergente che si colloca all’intersezione tra biologia, informatica, chimica e fisica. Si propone di utilizzare sistemi biologici, come il Dna, le proteine e le cellule, per eseguire calcoli o processare informazioni. A differenza dei computer tradizionali, che si basano su circuiti elettronici e semiconduttori per operare, i biocomputer sfruttano processi biologici intrinseci, come le reazioni biochimiche e le interazioni molecolari, per risolvere problemi computazionali. Questo approccio promette di superare i limiti dei calcolatori elettronici in particolari ambiti, offrendo dispositivi più efficienti, adattabili e capaci di rispondere a esigenze specifiche in settori come la medicina, la biotecnologia e la ricerca scientifica.
I fondamenti
Entriamo solo un poco di più nei dettagli di questo promettente sistema di calcolo. Il biocomputing si basa su principi distintivi che lo differenziano dai metodi di calcolo convenzionali. In un computer tradizionale, le informazioni vengono rappresentate come bit binari (0 e 1) che vengono elaborati attraverso circuiti elettronici. Nel biocomputing, invece, i dati sono rappresentati da molecole biologiche, come il Dna o l’Rna, e vengono elaborati tramite processi biochimici. Per fare un esempio, nel calcolo basato sul Dna, la capacità della molecola di immagazzinare informazioni in sequenze specifiche di basi nucleotidiche viene sfruttata per codificare dati e risolvere problemi, con le stesse reazioni chimiche che avvengono in queste molecole che permettono di eseguire operazioni logiche complesse. Un elemento chiave del biocomputing è quindi la sua capacità di sfruttare la natura parallela dei sistemi biologici.
Mentre i computer tradizionali eseguono di fatto una una serie di operazioni sequenziali i biocomputer possono sostenere simultaneamente molteplici processi, grazie alla struttura molecolare del Dna e all’interazione simultanea tra molecole. Questo consente di risolvere problemi complessi, con una velocità e un’efficienza che ai sistemi di calcolo tradizionali sarebbe preclusa.
Ancora più interessante la possibilità per i sistemi di biocomputing di assicurare una maggiore efficienza energetica. I biocomputer, infatti, non necessitano di grandi quantità di energia elettrica per funzionare, poiché sfruttano reazioni chimiche naturali, aspetto che contribuisce a qualificarli come una soluzione potenzialmente più sostenibile rispetto ai calcolatori tradizionali. I limiti della tecnologia sono invece da individuare nelle sfide legate alla scalabilità, alla standardizzazione e alla stabilità dei sistemi biologici utilizzati.
Tre tipologie di sistemi
Il biocomputing attuale prevede già diverse tipologie di dispositivi, ciascuna progettata per specifiche applicazioni. In particolare se ne individuano tre: i biocomputer biochimici, quelli meccanici e i sistemi di calcolo bioelettronici. I primi si distinguono proprio per la capacità di sfruttare le reazioni chimiche all’interno di sistemi biologici per eseguire calcoli. In questo contesto, molecole specifiche fungono da input, mentre le reazioni tra queste molecole rappresentano operazioni logiche. Questo approccio è particolarmente utile quindi per simulare reti metaboliche o analizzare processi chimici complessi. I biocomputer meccanici sfruttano invece le proprietà fisiche delle molecole biologiche per rappresentare informazioni. Ad esempio, proteine o molecole di Dna possono assumere configurazioni diverse in risposta a stimoli chimici o fisici, e ogni configurazione può corrispondere a un seguente stato logico. Si parla in questi casi di sistemi di biocomputing promettenti per applicazioni legate alla nano-medicina e alla diagnostica avanzata. Infine, i biocomputer bioelettronici combinano materiali biologici con componenti elettronici per creare dispositivi ibridi. Questi sistemi utilizzano proprietà come i potenziali elettrici delle membrane cellulari per facilitare l’interazione tra segnali biologici ed elettronici. Si parla in questi casi di tecnologie interessanti per lo sviluppo di interfacce uomo-macchina avanzate, come i dispositivi impiantabili per il monitoraggio della salute.
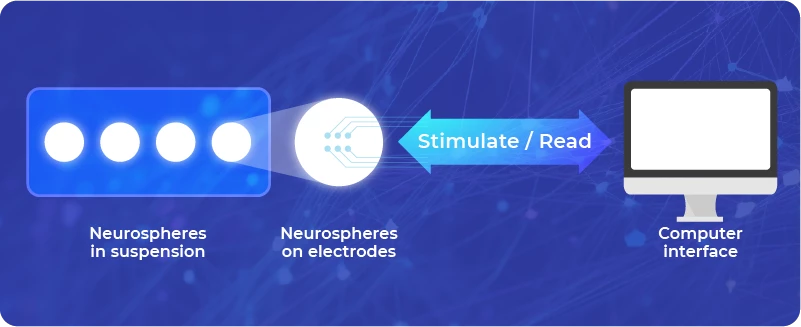
Le applicazioni concrete
Il potenziale applicativo del biocomputing è vasto, include settori cruciali come la medicina, la biotecnologia e l’informatica stessa. Una delle aree più promettenti è quella della medicina personalizzata, dove i biocomputer possono essere progettati per rilevare specifici biomarcatori nel corpo umano e fornire terapie mirate. Ad esempio, sono in fase di sviluppo microrganismi sintetici capaci di identificare molecole associate a malattie come il cancro e di rispondere rilasciando farmaci terapeutici in modo mirato. Un approccio che può rappresentare quindi un passo significativo verso trattamenti più efficaci e meno invasivi. Abbiamo già fatto riferimento poi al potenziale differenziante legato al calcolo parallelo, grazie alla capacità intrinseca dei sistemi biologici di eseguire molteplici operazioni contemporaneamente. Questa caratteristica serve per affrontare problemi computazionali complessi che richiedono un’analisi simultanea di grandi quantità di dati, e quindi sono proprio il sequenziamento del genoma umano o la progettazione di nuovi farmaci a beneficiarne maggiormente.
Biocomputing, le sfide
Nonostante il potenziale, il biocomputing presenta diverse sfide che devono essere affrontate per garantire il suo sviluppo e la sua applicazione su larga scala. Una delle principali difficoltà riguarda la complessità intrinseca dei sistemi biologici. I sistemi viventi sono variabili e influenzati da fattori ambientali, il che può rendere difficile prevedere il comportamento di un biocomputer e garantire la riproducibilità dei risultati di calcolo.
Questi sistemi, inoltre, sono difficili da realizzare e la loro effettiva scalabilità è ancora da provare. La creazione di molecole biologiche o sistemi cellulari su larga scala richiede infrastrutture sofisticate e costose, oltre a competenze specialistiche in biologia molecolare e ingegneria. Sono ostacoli che rendono difficile la transizione del biocomputing dalla fase sperimentale all’applicazione commerciale.
Terzo aspetto, forse quello davvero centrale, l’uso di componenti biologici, come neuroni o organoidi umani, solleva importanti questioni etiche. L’idea di utilizzare tessuti cerebrali per costruire processori viventi suscita preoccupazioni legate alla possibilità di sviluppare una forma di coscienza in questi sistemi. È fondamentale stabilire linee guida etiche rigorose per affrontare queste problematiche e garantire un uso responsabile della tecnologia.
La ricerca
Come spesso capita sulle ricerche di frontiera, in prima linea a livello globale troviamo sul tema le ricerche del Mit (Massachusets Institute of Technology) che conduce studi riguardo l’integrazione di organoidi cerebrali umani con chip elettronici per eseguire compiti computazionali. Gli organoidi cerebrali – strutture cellulari tridimensionali artificiali, generate a partire da cellule staminali umane – sono stati collegati a chip elettronici, dimostrando la capacità di svolgere compiti come il riconoscimento vocale. Questo approccio ibrido potrebbe portare allo sviluppo di biocomputer più efficienti e adattabili rispetto ai tradizionali sistemi elettronici. Un altro studio del Mit (in questo caso risaliamo fino al 2022) ha utilizzato il batterio Escherichia Coli per risolvere labirinti chimici, dimostrando la potenzialità dei biocomputer nel risolvere problemi complessi attraverso la cooperazione tra cellule. In questo esperimento, diverse popolazioni di Escherichia coli hanno lavorato insieme come un computer distribuito, elaborando informazioni chimiche per trovare la soluzione.
Un recente articolo comparso sulla rivista Imaging Neuroscience (2024), spiega l’utilizzo del biocomputing come frontiera emergente nella ricerca, enfatizzando l’integrazione tra biologia e informatica per affrontare le complessità del cervello umano. Si evidenzia come il biocomputing sfrutti modelli computazionali avanzati per simulare e analizzare i processi cerebrali, dalla scala molecolare a quella sistemica. Un elemento chiave in questo ambito sarebbe l’uso di piattaforme digitali, come Ebrains (piattaforma tra l’altro europea), che facilitano la condivisione e l’integrazione di dati neuroscientifici su larga scala, promuovendo una comprensione multidimensionale del cervello. Ecco allora che il biocomputing viene presentato come un metodo innovativo per esplorare i meccanismi alla base di funzioni cognitive e disfunzioni neurologiche, con applicazioni potenziali nella medicina personalizzata e nello sviluppo di tecnologie ispirate al cervello.
Anche in Italia, le ricerche nel campo del biocomputing stanno facendo progressi con il contributo di istituzioni accademiche e startup innovative. Presso l’Università di Trento, per esempio, il Dipartimento Cibio ha sviluppato cellule artificiali capaci di rilevare molecole prodotte da tumori e di rilasciare farmaci specifici. Questo approccio rappresenta un esempio di come il biocomputing possa essere applicato alla terapia genica e alla medicina di precisione. E così, presso l’Università di Padova, il gruppo BioComputing UP si occupa di modellare sistemi biologici complessi utilizzando tecniche di biologia computazionale. Le ricerche sono orientate alla progettazione di farmaci innovativi e allo studio dei meccanismi molecolari che regolano il funzionamento delle cellule.
Nel panorama delle startup, ci ha interessato infine la ricerca della Svizzera FinalSpark che ha recentemente sviluppato un prototipo di biocomputer basato su neuroni umani conducendo esperimenti in remoto su neuroni biologici in vitro. Questa tecnologia apre nuove prospettive per lo sviluppo di processori biologici in grado di apprendere e adattarsi, superando i limiti dei calcolatori convenzionali.
© RIPRODUZIONE RISERVATA


: AI sovrana sprona le aziende")




")