





: AI sovrana sprona le aziende")


: Nuova sede, stessa strategia")











: Business AI, cambia il fare impresa")














Da novembre 2022 l’intelligenza artificiale generativa è diventata di dominio pubblico, soprattutto per merito di ChatGpt di OpenAI. La disponibilità di strumenti conversazionali, attraverso una semplice interfaccia Web, ha avuto l’effetto di generare un hype. Le intelligenze artificiali in verità fanno parte della dotazione degli strumenti IT da molto più tempo, per esempio sono parte integrante di diversi tool predittivi e di tutta la sfera di piattaforme auto/manutentive che i vendor definiscono come “autonome”.
La GenAI, progettata per generare testo, immagini, musica, codice e altro, utilizza anch’essa tecniche avanzate di machine learning ma è dedicata alla generazione di contenuti basati su input e regole apprese (non necessariamente nuovi, nel senso che la GenAI non ha comunque la capacità di aggiungere sapere ed è sempre una Narrow AI, un’AI articolata, ma ancora relativamente debole).
Gli algoritmi di GenAI più avanzati si basano su reti neurali profonde. Fanno riferimento ad architetture complesse per addestrare modelli come sono le Generative Adversarial Networks (Gans), ai Variational Autoencoders (Vaes) – tipi di rete neurale artificiale utilizzati per l’apprendimento dei modelli generativi che apprendono dalle rappresentazioni compresse dei dati di addestramento – e ai modelli di trasformatori come Gpt (Generative Pre-trained Transformer).
Le Gan, semplificando il più possibile, sono composte da due reti neurali in competizione, una generativa (che crea contenuti) e una discriminativa (che valuta il contenuto generato). La rete generativa cerca quindi di migliorare costantemente le prestazioni in “dialettica” con la rete discriminativa, portando a creazioni sempre più realistiche, i Vaes utilizzano invece una combinazione di encoder e decoder per generare nuovi dati simili al set di addestramento. Tornano utili quindi per l’interpolazione tra punti di dati e la generazione di variazioni di dati esistenti. Un ruolo delicatissimo è, infine, proprio quello giocato dai trasformatori che rappresentano l’architettura di rete neurale progettata per trasformare o modificare una sequenza di input in una sequenza di output. Facile comprendere come da essi dipenda anche la qualità percepita delle AI generative. Arriviamo all’acronimo più conosciuto, Gpt.
Significa appunto Generative Pre-trained Transformer ed è il modello di linguaggio che utilizza un’architettura di trasformatori per comprendere e generare testo. È addestrato su vasti set di testo e contenuti eterogenei e può generare risposte coerenti e contestuali a partire da un prompt iniziale.
Volendo schematizzare e semplificare al massimo mentre l’obiettivo principale dell’AI generativa è la creazione di contenuti – che, così come presentati, non esistono nei dati di addestramento – e produrre infine output nuovi e originali, l’AI generale si occupa di risolvere problemi, prendere decisioni, riconoscere pattern, e automatizzare compiti basati su regole e dati preesistenti.
Tra le AI generative più conosciute possiamo facilmente citare ChatGpt di OpenAI, Gemini di Google, l’assistente Copilot di Microsoft, Claude di Anthropic, Amazon Bedrock e Meta AI di Meta. E quattro sono di fatto i casi d’uso più utilizzati: la generazione di testo, immagini (per esempio con Dall-e), suoni (MuseNet), il coding tra cui merita una segnalazione specifica per l’estensione d’uso GitHub Copilot. In un rapido confronto vedremo che proprio alcuni dei concetti base spiegati tornano utili.
Generative AI a confronto, ChatGpt
ChatGpt di OpenAI, per esempio, è basata sull’architettura Generative Pre-trained Transformer (Gpt), una delle innovazioni più significative nel campo del processamento del linguaggio naturale (Nlp). La versione più recente, Gpt-4o, utilizza miliardi di parametri per modellare il linguaggio umano in modo accurato. La chiave del successo di ChatGpt risiede proprio nell’uso di tecniche di pre-training su enormi volumi di testo, seguite da un fine-tuning supervisionato e di rinforzo per affinare le risposte (che comunque non sono esenti da allucinazioni e bias). In particolare, l’architettura Gpt si basa su un modello di trasformatori, che utilizza specifici meccanismi di attenzione per pesare l’importanza di diverse parti del testo durante la generazione.
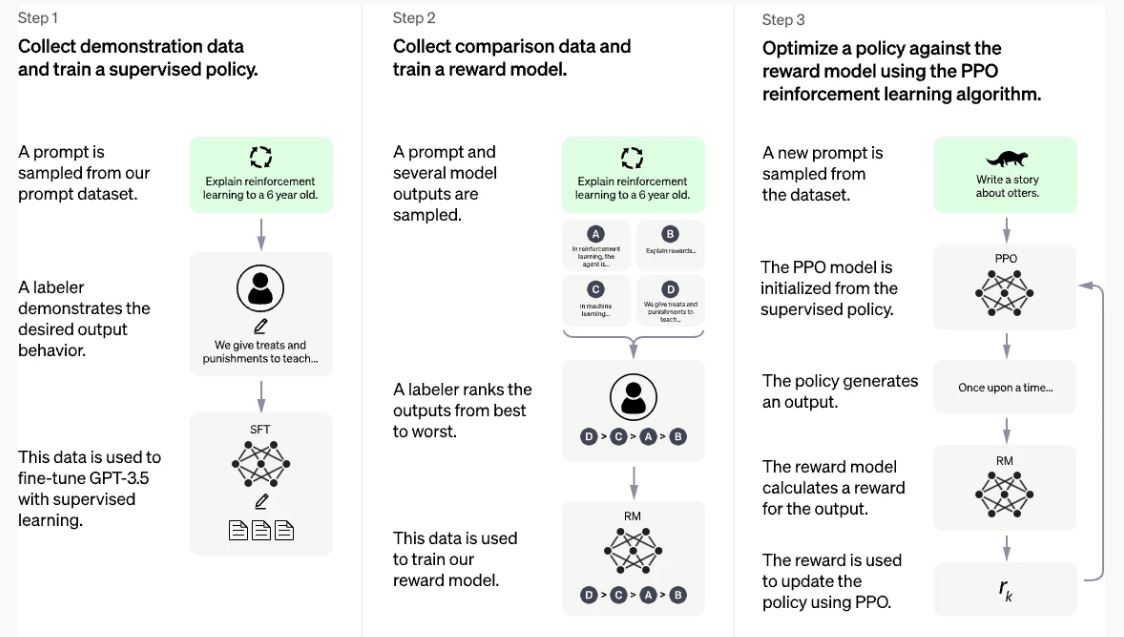
Questo meccanismo consente al modello di gestire lunghe sequenze di testo e di mantenere la coerenza contestuale su lunghe ‘distanze’ mnestiche (anche se il termine è in parte improprio, considerato il suo ambito di applicazione smaccatamente cognitivo). La fase di pre-training avviene su enormi dataset di testo raccolti dalle reti, permettendo al modello di apprendere una vasta gamma di informazioni linguistiche e di conoscenza generale. Successivamente, il fine-tuning supervisionato utilizza dati annotati specifici per migliorare le risposte del modello in contesti particolari, come rispondere a domande tecniche o seguire istruzioni dettagliate. Infine, il rinforzo dall’apprendimento umano (Reinforcement Learning from Human Feedback, Rlhf) viene impiegato per migliorare ulteriormente il modello, facendo valutare le risposte generate da esseri umani e aggiornando il modello in base a queste valutazioni.
ChatGpt si distingue quindi in primis per la sua versatilità. Può essere utilizzata in una vasta gamma di applicazioni, dalla scrittura creativa alla risoluzione di problemi tecnici (e dispone già oggi di diverse versioni personalizzate per specifici scopi, per esempio Write for Me, proprio per generare articoli). La qualità del testo è spesso indistinguibile da quello scritto da un essere umano (sui contenuti potremmo invece ancora confrontarci), rendendolo uno strumento prezioso per scrittori, sviluppatori e professionisti del marketing. Tuttavia, ChatGpt non è priva di limiti. Nonostante gli sforzi di OpenAI per ridurre i bias, il modello riflette i medesimi limiti presenti nei dati di addestramento. Inoltre, controllare il contenuto generato può essere difficile senza una supervisione significativa, il che pone sfide in termini di precisione e affidabilità.
Google Gemini
Gemini di Google ci piace definirla come AI generativa integrata. La sua migliore qualità è probabilmente, infatti, la forte capacità di integrazione e contestualizzazione delle informazioni. Basata dalle origini (nel 2019) sull’architettura dei modelli T5 (Text-To-Text Transfer Transformer), oggi T5X, Gemini è progettata per convertire tutte le attività Nlp (Natural Language Processing) in un problema di trasformazione testo/testo, migliorando la versatilità e l’efficienza del modello. L’architettura utilizza una configurazione encoder-decoder, dove l’encoder processa l’input e il decoder genera l’output. Questo approccio permette al modello di gestire una vasta gamma di compiti Nlp, trasformando ogni problema in una sequenza di trasformazioni testuali.

Gemini beneficia dell’accesso a una vasta gamma di dati e servizi di Google, migliorando significativamente la qualità e la pertinenza delle risposte. Tra i principali vantaggi la sua capacità di utilizzare le capacità di ricerca di Google per fornire risposte, allo stesso tempo la sua efficacia a noi pare ridotta se utilizzata al di fuori dell’ecosistema Google, ma il modello rappresenta comunque un esempio di come l’integrazione con grandi ecosistemi di dati possa migliorare le capacità delle AI generative.
Microsoft Copilot
Di Copilot di Microsoft, sviluppato dall’azienda in collaborazione con OpenAI, prima ancora della sua integrazione nei processi Microsoft 365 (per un utilizzo di fatto già conosciuto dalla maggior parte delle persone che lavorano) ci piace sottolineare le capacità di assistenza nello sviluppo di codice e nelle attività di programmazione. Microsoft Copilot è la soluzione che nasce dalla combinazione dei large language model di OpenAI con i dati di Microsoft Graph, ma GitHub Copilot è l’assistente virtuale sviluppato in collaborazione con OpenAI e GitHub per semplificare le attività di programmazione e sviluppo. Integrato strettamente con GitHub, Copilot può ‘capire’ i contesti di coding e suggerire frammenti di codice, completare funzioni e persino scrivere interi blocchi basati su commenti e descrizioni fornite dagli utenti. Questa capacità di generare codice in modo contestuale rende Copilot uno strumento potente per i programmatori, aumentando la loro produttività e riducendo il tempo necessario per scrivere e fare debug del codice; allo stesso tempo può rappresentare un valido aiuto anche in quei casi in cui i linguaggi sono meno conosciuti.
Con una nota: GitHub Copilot è addestrato su tutti i linguaggi che compaiono nei repository pubblici. Per ogni linguaggio, la qualità dei suggerimenti può dipendere dal volume e dalla diversità dei dati di addestramento per quel linguaggio. JavaScript è ben rappresentato nei repository pubblici ed è quindi ben supportato anche da GitHub Copilot, ma non sempre è così. Solo per entrare poco di più nei dettagli l’architettura su cui si basa Copilot, utilizza un approccio transformer simile a Gpt, ma è cresciuta – appunto – su un vasto corpus di codice sorgente proveniente da repository pubblici, come GitHub. Questa specializzazione consente di comprendere sintassi e semantica di vari linguaggi di programmazione, fornendo suggerimenti contestuali basati sul codice scritto dall’utente. Uno dei principali vantaggi di Copilot è quindi la sua capacità di apprendere continuamente dai repository di codice GitHub, migliorando costantemente la qualità dei suggerimenti.
Tuttavia, la qualità dei suggerimenti può variare e richiede una supervisione da parte di programmatori esperti per garantire che il codice generato sia corretto e sicuro. Inoltre, Copilot potrebbe non comprendere completamente il contesto di alcuni progetti complessi, limitando la sua efficacia in scenari avanzati.
Anthropic Claude
A caratterizzare Claude di Anthropic (che oggi beneficia di importanti investimenti da parte di Amazon) è invece il rigore su sicurezza e attenzione etica. Questo nelle intenzioni dei fondatori – Dario Amodei, ex dipendente di OpenAI, e sua sorella Daniela Amodei – che hanno lasciato OpenAI proprio a causa delle preoccupazioni sulla potenziale commercializzazione delle tecnologie AI e sulla necessità di dare priorità alla sicurezza e alle considerazioni etiche nello sviluppo dell’AI. Claude, oggi pubblica nella versione 3.5, utilizza un’architettura transformer simile a Gpt, ma con modifiche progettuali mirate agli scopi indicati.
Il modello è addestrato con un focus sulla minimizzazione dei rischi e sull’evitare comportamenti indesiderati. Questo include tecniche avanzate di reinforcement learning e feedback umano per garantire che il modello rispetti le linee guida etiche. A impressionare, nell’utilizzo, è la percezione di come Claude sia in grado di capire e generare testo con una profonda comprensione del contesto, tuttavia i suoi modelli richiedono risorse significative per l’addestramento e il mantenimento, il che può rappresentare una barriera significativa per le piccole imprese o sviluppatori indipendenti.
Amazon Bedrock
L’intuizione di Amazon, anche nello sviluppo dei suoi strumenti di AI generativa, è stata invece quella di agganciare il suo utilizzo direttamente e in modo solido ai workload Aws, quindi a supporto del cloud, con Amazon Bedrock. Questo modello si distingue per la sua capacità di scalare e gestire carichi di lavoro intensivi che poggiano sull’infrastruttura di Amazon. Bedrock può essere utilizzato per una varietà di applicazioni, dalla generazione di testo alla creazione di modelli di machine learning, beneficiando della flessibilità e della scalabilità offerte da Aws.
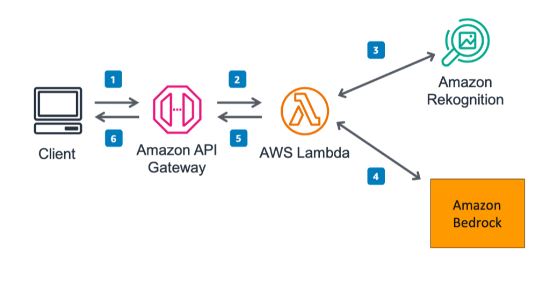
L’architettura di Amazon Bedrock si basa sempre su transformer ma beneficia dell’ampia scalabilità infrastrutturale di Aws. Questo rende Bedrock adatto per applicazioni aziendali su larga scala e tuttavia, l’utilizzo può essere costoso, soprattutto per piccole imprese o sviluppatori individuali. I costi associati all’infrastruttura Aws possono rappresentare una barriera significativa ed inoltre il suo utilizzo può richiedere una conoscenza approfondita dei servizi Aws per spremerne a fondo i vantaggi, il che rappresenta una barriera per gli utenti meno esperti.
Meta AI
Anche lo sviluppo di Meta AI di fatto è prima conseguenza degli interessi di Meta e quindi l’ottimizzazione per i social media. Parliamo in questo caso di un Llm progettato per generare risposte umane su misura per i contesti dinamici delle comunicazioni sociali, migliorando l’interazione e l’engagement degli utenti. Un Llm poi evoluto questa primavera in Llama 3, aperto, addestrato su 140 miliardi di parametri (contro i 70 mld della precedente versione).
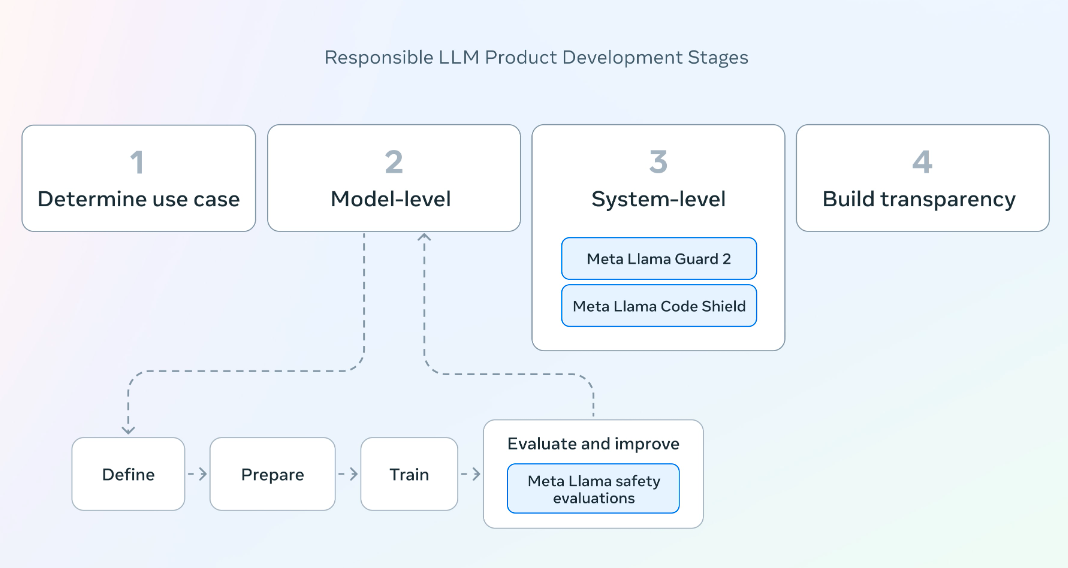
La Meta AI può essere personalizzata per riflettere la personalità e lo stile degli utenti, rendendola uno strumento potente per migliorare l’esperienza utente nelle piattaforme sociali, ma anche con tutti i rischi connessi a questa tipologia di utilizzo, anche perché l’architettura di Meta AI utilizza modelli avanzati di Nlp, ma l’addestramento su dataset di conversazioni e interazioni social se consente a Meta AI di generare risposte che ‘risuonano’ con gli utenti, proprio su questo punto mostra la sua debolezza. Meta AI deve sostenere sfide significative in termini di privacy e bias, anche perché in nessun altro luogo, come sui social, è facile riscontrare bias persistenti che richiedono mitigazione, un punto su cui MetaAI in Llama 3 ha lavorato con l’introduzione di nuovi strumenti di fiducia e sicurezza tramite Llama Guard 2, Code Shield e CyberSec Eval 2.
GenAI, i trend di sviluppo
Il futuro delle GenAI promette ulteriori innovazioni e sviluppi, con diverse aree chiave che meritano attenzione. Uno degli aspetti più importanti è lavorare sull’AI alignment e sulla sicurezza dei modelli di AI. l’AI alignment mira a orientare i sistemi di AI verso gli obiettivi, le preferenze e i principi etici previsti da una persona o da un gruppo. Un sistema di AI è considerato allineato se ‘promuove’ i suoi obiettivi previsti. Garantire che le AI generative siano allineate agli interessi umani e prive di comportamenti dannosi è essenziale. Questo include lo sviluppo di tecniche avanzate di reinforcement learning (abbiamo incontrato nell’analisi AI che ne fanno uso) e feedback umano per migliorare l’allineamento etico e ridurre i bias, ma è un compito questo anche complesso, per i progettisti di AI perché è difficile trovare il modo di specificare l’intera gamma di comportamenti desiderati e indesiderati.
Un’altra area di sviluppo emergente è rappresentata dalle Rag AI (Retrieve-and-Generate AI). Questi modelli non solo generano contenuti, ma recuperano informazioni da grandi database per migliorare la precisione e l’affidabilità delle risposte. Le Rag AI proprio per questa modalità di operare generano risposte più accurate e contestuali. Questa tecnologia promette di migliorare significativamente la qualità delle risposte generate, rendendole più informative e utili per gli utenti. L’integrazione multimodale è infine un’altra frontiera promettente ed in parte già traguardata. I modelli multimodali sono in grado di gestire testo, immagini, video e suoni contemporaneamente, aprendo nuove possibilità per applicazioni avanzate. Questa capacità di combinare diverse modalità di dati rende i modelli multimodali particolarmente potenti per applicazioni che richiedono una comprensione complessa e una generazione di rich contents. Un ultimo ulteriore punto su cui le aziende oggi lavorano è avvicinare l’AI all’industria, al business incluse le piccole imprese e gli sviluppatori individuali. Questo includerà lo sviluppo di modelli più efficienti dal punto di vista computazionale e l’ottimizzazione delle risorse di addestramento.
© RIPRODUZIONE RISERVATA

")

: AI sovrana sprona le aziende")




")