





: AI sovrana sprona le aziende")


: Nuova sede, stessa strategia")











: Business AI, cambia il fare impresa")














Secondo Idc, l’ecosfera dei dati nel 2019 poteva essere quantificata a livello globale in 40 Zettabyte. Entro il 2025 questo valore sarà cinque volte più alto. I dati sono riconosciuti come l‘asset più importante delle aziende. Vale anche per le piccole, oltre che per l’enterprise. E vale per tutte le geografie.
In Italia, questa consapevolezza si fa strada in ogni comparto. Solo l’analisi dei dati permette di conoscere a fondo i clienti e quindi di indirizzare lo sviluppo di prodotti e servizi nella giusta direzione. Valorizzare le informazioni non è tuttavia un compito facile. Lo è raccoglierle, ma proteggerle, organizzarle e correlarle nel modo corretto, in modo che generino informazioni importanti e valide per i processi decisionali, rappresentano ancora aspetti critici.
I problemi sono in primis la difficoltà di fare dialogare i silo di dati disponibili generati dai diversi comparti. I dati del marketing quasi mai sono correlati con quelli generati direttamente dal prodotto, quelli del finance ancora meno, e così anche progetti di analisi promettenti sembrano non portare i risultati sperati. Non solo, parte dei dati viene ritenuta esclusiva proprietà dell’azienda; si pensa che evitarne la condivisione con i partner della filiera sia la soluzione migliore, e così facendo però ci si limita e ci si esclude da una serie di possibilità.
Tra i driver che permettono di superare una serie di ostacoli, le soluzioni di machine learning e AI sono le più importanti e promettenti. Con queste tecnologie è possibile individuare nuove possibilità di business e di contenimento dei costi a patto però di riuscire ad attingere a set di dati anche molto eterogenei e farli dialogare con quelli prodotti internamente.
Si pensi, per esempio nella logistica, alle relazioni tra le condizioni meteo, il traffico e il bisogno di inviare o ricevere merci. Alle possibilità di risparmio e di efficienza a patto di riuscire a fare tesoro di informazioni così eterogenee tra loro. Per diverse industry il dialogo dei dati della propria azienda con quelli delle altre organizzazioni si sta dimostrando essenziale.

Basterebbe fare l’esempio delle analisi con l’AI – come nel caso delle emergenze sanitarie attuali – su set di dati condivisi tra Paesi, case farmaceutiche, realtà di assistenza medica, organizzazioni pubbliche. E all’accelerazione possibile per la ricerca. Lo stesso nell’ambito automotive, con l’effettiva cooperazione tra le case automobilistiche, gli organismi come Anas, i rilevatori di traffico, etc.
Nel prossimo futuro, senza dubbio, la valorizzazione dei dati dovrà fare i conti con la capacità di condividerli nell'”ecosistema”, prima internamente, e poi con le altre realtà.
Non si tratta affatto di rinunciare al business generato dalle informazioni, si tratta al contrario, di essere in grado di valorizzarle, metterle in sicurezza, scambiarle con procedure e formati open, su piattaforme open.
Passaggi tutti che possono rappresentare occasioni ulteriori di business: comprare, scambiare e vendere dati immediatamente utilizzabili, per esempio. In questo modo “allenare” i sistemi di machine learning è più proficuo e permette di raggiungere prima i risultati attesi.
Ecosistema di dati, 4 pilastri
Proprio da queste riflessioni si individuano quattro caratteristiche chiave di un ecosistema ideale: in primis la sicurezza, quindi l’affidabilità delle informazioni, l’utilizzabilità e infine la conformità.
Partiamo dall’ultimo aspetto. I dati sono conformi quando rispettano le compliance relative alle normative nazionali e sovranazionali (il Gdpr da noi, il California Act, negli Usa, etc.). Non ci riferiamo certo solo alle regolamentazioni sulla privacy. Devono essere utilizzabili e questo quindi determina che uno scambio di dati già “standardizzati”, rispetto allo stesso scambio sulla base di dati grezzi, ha un valore decisamente più alto. Anche in questo caso “la lavorazione, l’estrazione già di un’informazione utilizzabile” devono essere riconosciute come passaggi di trasformazione che aggiungono valore al dato grezzo.
Le informazioni devono poi essere affidabili, altrimenti è chiaro che le analisi successive più che produttive saranno rischiose. In questo caso, già oggi è possibile assicurare valore all’informazione in relazione alla metodologia di acquisizione e alle possibili certificazioni applicabili (blockchain tra le tecnologie abilitanti).
Da qui l’ultimo aspetto, il primo per importanza, la sicurezza. Oggi non è pensabile rinunciare alle tecnologie di crittografia da utilizzare sia sui dati a riposo, sia su quelli in transito. Allo stesso tempo si dovrebbe sempre dare conto, sfruttando il reverse engineering, anche della validità degli algoritmi. Non è vero proprio per nulla che l’AI sia una grande scatola nera e chi vuole farlo credere sta giocando una partita sbagliata.
Ecosistema, come scegliere i dati
Le aziende non hanno ancora compiuto i passi necessari per riuscire ad accedere effettivamente alle grandi moli di dati esterne e a beneficiarne. Soprattutto perché non si è mai pensato di farlo prima. Identificare quali dati servono, valutarli, reperirli, stringere partnership opportune richiedono competenze importanti, se poi si tratta di integrare i set esterni con quelli interni, è evidente quanto una sfida di questo tipo sia anche rischiosa.
Gartner identifica queste figure come “data curator”. Gli stessi analisti di Gartner classificano le tipologie di insights provider in base ai servizi offerti, per aiutare le aziende ad orientarsi quando decidono di “collegarsi” a un ecosistema di dati.
Tre i modelli. E’ possibile scegliere un approccio semplice chiedendo a data broker una raccolta di dati da fonti eterogenee, più o meno “ricondizionati”, ma comunque pronti per essere utilizzati da un’applicazione o da un device, per esempio in un sistema IoT (1). Oppure preferire subito i servizi di Smart Data (2); in questo secondo caso Gartner spiega come i dati siano già “potenziati” con l’applicazione di regole analitiche standard. Una scelta, per esempio, preferita dal marketing e dalle agenzie di rating, o ancora è possibile arricchire il patrimonio dei dati disponibili puntando ad ottenere informazioni cui sono già state applicate richieste analitiche specifiche (3).
I DC non sono pronti per l’ecosistema
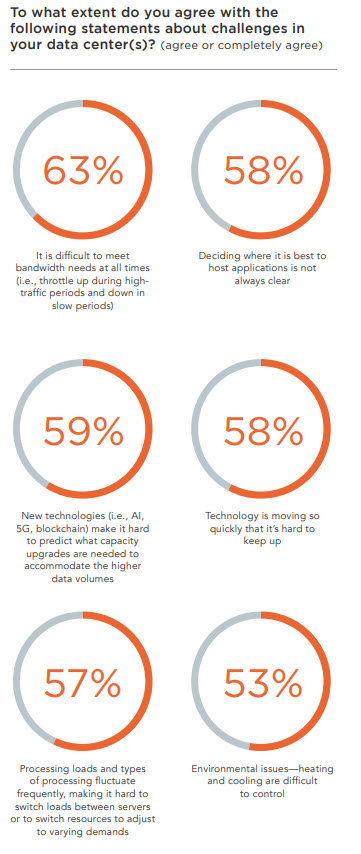
Dal punto di vista tecnologico, la cultura di un ecosistema per i dati richiede l’evoluzione del data center. Ne abbiamo già riconosciuti alcuni tratti nei nostri contributi: una presenza all’edge, ma anche l’iperconnettività, l’aggiornamento continuo, la capacità di elaborare informazioni di diversa provenienza dall’edge al cloud e restituire valore in tempo reale. Una recente ricerca Vertiv, su oltre 150 tra dirigenti ed ingegneri di aziende a livello mondiale evidenzia, da questi punti di vista, una seria di ritardi e di “discordanze”.
Poco più del 10% dei dirigenti sostiene che i DC aziendali vengono aggiornati secondo le esigenze, ma lo pensa appena l’un percento degli ingegneri. La maggior parte delle aziende è in ritardo per quanto riguarda la capacità di pianificare, prevedere e poi soddisfare i requisiti di elaborazione per raggiungere gli obiettivi.
Circa il 63% del campione riconosce di avere difficoltà nel soddisfare le esigenze di banda larga, anche nei momenti più critici. E sicurezza, backup e capacità di implementare nuove tecnologie restano le caratteristiche più comunemente identificate in grado di offrire un vantaggio competitivo, ma spesso ancora disattese.
Da questo scenario emerge prima di tutto il problema della complessità. Da un lato le aziende riconoscono di non riuscire a farcela valorizzando esclusivamente i dati disponibili internamente, dall’altro il ruolo che Gartner identifica come “data curator” è un ruolo complesso. Integrare i dati esterni nel proprio ecosistema, e ancora di più rendere disponibili parte dei propri ad un ecosistema esterno, in ogni caso rappresentano una scommessa vincente per i prossimi anni.
© RIPRODUZIONE RISERVATA
")


: AI sovrana sprona le aziende")




")