





: AI sovrana sprona le aziende")


: Nuova sede, stessa strategia")











: Business AI, cambia il fare impresa")














Semplificare l’utilizzo delle tecnologie container, grazie ad un’offerta software defined storage specifica per i carichi di lavoro nativi in cloud, ha portato lo scorso autunno Datacore all’acquisizione di Mayadata con cui era già in corso una proficua partnership. Datacore – riconosciuta per la proposizione software defined per lo storage a blocchi, file, oggetti e Hci – con l’acquisizione in un certo senso ha “chiuso il cerco” estendendo la propria offerta anche all’ambito container-native.
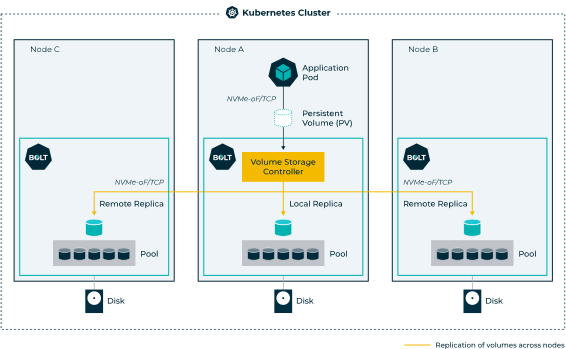
E Datacore Bolt, annunciato in questi giorni, rappresenta il primo risultato di quell’acquisizione. La proposta colma la mancanza di una soluzione in grado di offrire provisioning dinamico di storage persistente per gli ambienti Kubernetes, basato sulle tecnologie Nvme-Over Fabrics in cloud come on-premise, in uno scenario in cui l’utilizzo crescente di Kubernetes ha posto ancora più enfasi sullo storage “progettato” da zero per i deployment containerizzati e distribuiti.
Si tratta di una proposta specifica per gli ambienti containerizzati, che facilita il deployment ed il rilascio del software in produzione preservando l’agilità richiesta dagli ambienti DevOps. E proprio grazie alla possibilità di sfruttare i vantaggi di Nvme e del protocollo Over Fabric/Tcp, Bolt supporta la scelta di un’architettura di storage componibile e disaggregata, e riduce sovraccarichi e lentezze che si riscontrano con altri prodotti di storage.

Ne spiega meglio la natura così Dave Zabrowski, Ceo di Datacore Software: “Ci siamo resi conto che i container avrebbero segnato il cambio di passo anche per lo storage dei dati con un impatto unico sul deployment e sulla reattività delle applicazioni basate sui microservizi“.
In un mercato in cui le tecnologie Nvme Over Fabrics e servizi dati indipendenti dalla piattaforma utilizzata sono molto richieste con Bolt, Datacore prosegue lo sviluppo avviato da Mayadata per un software scalabile ed affidabile tale da “consentire alle organizzazioni di fare il salto nel mondo containerizzato e rispondere rapidamente ai cambiamenti”.
Anche perché le tradizionali infrastrutture di storage non sono in grado di soddisfare le esigenze di persistenza e portabilità dei dati dei moderni workload stateful, infatti, nell’utilizzo DevOps, la loro dipendenza da attività manuali ripetitive rallenta le pipeline di integrazione e distribuzione continua (CI/CD), riducendo i benefici che l’organizzazione in container può offrire.
Bolt quindi elimina i ritardi causati dallo storage tradizionale negli ambienti Kubernetes e permette quindi di accelerare la reattività dei workload stateful tramite accesso a bassa latenza alle unità Nvme. Questo è possibile perché di fatto viene rimpiazzata la gestione complessa della storage dall’automazione nativa offerta da Kubernetes, con anche un migliore controllo, al contempo, sullo storage. Migliora quindi la portabilità dei servizi, vengono eliminate le dipendenze dal kernel dei diversi sistemi operativi e si approda all’ideale di una pipeline CI/CD tutta orchestrata direttamente da Kubernetes.
La proposta si affianca agli altri strumenti Kubernetes utilizzati per il controllo della versione, la gestione della configurazione, ed il repository dei codici di automazione CI/CD, automazione dei test, monitoraggio e deployment. Lato utenti, Dinesh Majekar, direttore di Civo – service provider cloud-native che si basa esclusivamente su Kubernetes e utilizza Bolt da circa un anno – conferma così i vantaggi: “Sfruttando le potenzialità incorporate nel software OpenEbs, i team possono seguire un percorso verso l’agilità che consente di scalare l’infrastruttura Kubernetes per supportare le applicazioni stateful containerizzate e la pipeline DevOps, migliorando l’esperienza e l’efficienza delle applicazioni ad alta intensità di I/O tramite il solo Kubernetes”.
© RIPRODUZIONE RISERVATA


: AI sovrana sprona le aziende")




")