









: CX e intelligenza operativa")


: Proposta per cloud distribuito e AI")





: Progetti per il post Pnrr")
: 140 progetti Pnrr rivolti ai cittadini")














A guidare le strategie aziendali e le scelte del comparto IT è spesso la riduzione dei costi. A parità di prestazioni (ma non sempre salvaguardando l’affidabilità), l’IT manager è chiamato a dare conto delle sue scelte e per farlo in modo documentato ha bisogno di metriche. Il cloud, da questo punto di vista, insieme ai tanti benefici, ha reso più complicato mantenere il controllo, la vista dall’alto sui dati, e di sicuro ha cambiato anche alcune regole del gioco.
Per esempio i criteri di scelta delle architetture di storage.
Efficienza, interoperabilità, gestibilità, performance e resilienza possono essere indirizzate in modo diverso a seconda degli ambienti in cui le informazioni sono memorizzate e verranno poi utilizzate, vediamo come.
Secondo gli analisti, entro il 2025 i dati cresceranno superando i 200 Zettabyte. Solo rispetto a quattro anni fa, si tratterebbe di una crescita ben superiore al 1000%, probabilmente per difetto. Markets and Markets valuta in 88 miliardi di dollari il valore del mercato cloud storage nel 2022, erano 37 miliardi solo due anni fa.
Alla crescita quantitativa, un’analisi di Gartner affianca le sottolineature qualitative. Quando si parla di computing oggi i dati non sono sempre “documenti”, anzi, lo sono solo in una percentuale minima. Si tratta di informazioni non strutturate, che possono essere consumate certo, ma magari non necessariamente modificate. Pensiamo alle registrazioni dei sensori IoT, ma anche ai contenuti audio e video, e comunque ad informazioni anche eterogenee che contribuiscono ad alimentare le applicazioni di big data analytics, per esempio.
File storage
In questo contesto, è facilmente comprensibile come un sistema di storage gerarchico – con un file system, le directory, il file – quello per intenderci cui siamo abituati quando utilizziamo il pc – non permetta sul lungo periodo scalabilità, flessibilità e in fondo accessibilità adeguate. Il problema infatti non è solo disporre di dischi più grandi, quanto piuttosto di capire come organizzare le informazioni, e come mantenerle disponibili velocemente nel tempo. Questo sistema tuttavia è utilizzatissimo, su computer, server, è praticamente l’unica modalità di conservazione dei documenti conosciuta da chi utilizza i sistemi di computing tutti i giorni, perché indirizza bene le esigenze correlate.
Storage a blocchi
Lo storage a blocchi, per certi aspetti, già riesce a superare alcune delle limitazioni dei file storage (gerarchizzazione, lentezza, grandi volumi). L’approccio, quindi, è abbastanza diverso rispetto ai sistemi di file storage: in pratica i dati vengono archiviati in blocchi di informazioni come porzioni separate, anche disgiunti dall’ambiente di lavoro degli utenti, per permette di memorizzare i dati dove è più comodo al sistema, indipendentemente dalla piattaforma.
I file nel blocco non possono essere eseguiti né aperti ma ogni file può essere distribuito su più blocchi. Se ben configurato, un sistema di storage a blocchi è in grado di conservare i “pezzi” nell’ambiente più pertinente, quando l’informazione è richiesta è il sistema a riassemblare i blocchi di dati a ricostituire l’unità, grazie all’ID univoco è assegnato al blocco.
L’archiviazione a blocchi gestisce i dati come un insieme di blocchi numerati di dimensione fissa. L’archiviazione dei file opera a un livello superiore, quello del sistema operativo, e gestisce i dati come una gerarchia denominata di file e cartelle. Nell’archiviazione a blocchi l’informazione è spesso accessibile sfruttando protocolli come iScsi o Fibre Channel. Così come in quella a file tramite server Nas o “filer” per archiviazione di file, utilizzando Common Internet File System (Cifs) o Network File System (Nfs) come protocolli.
I vantaggi dello storage a blocchi sono prima di tutto la rapidità nel recuperare le informazioni, dato proprio dall’assenza di “annidamenti gerarchici” e dal fatto che lo strato storage è agnostico rispetto al sistema operativo. Lo svantaggio invece è dato dal fatto che si parla ancora di blocchi, all’interno di un server. Non di directory, ma di blocchi.
Spieghiamo: la declinazione infrastrutturale tipica di questo approccio sono le Storage Area Network. Un blocco di suo è sostanzialmente un indirizzo, e in un sistema San diversi blocchi formano un file. L’applicazione di storage in queste architetture decide dove archiviare i blocchi e le modalità di accesso, ma i singoli blocchi non dispongono di metadati, è il sistema storage, o l’applicazione, a controllare quindi il dato stesso.
Da qui gli ambiti di utilizzo ottimali individuabili nelle applicazioni transazionali come i database, e comunque in ogni caso in cui la quantità di dati è destinata a crescere anche in modo esponenziale, e tuttavia è anche necessario modificare ancora i dati, una volta memorizzati, o accedervi di frequente. Allo stesso tempo un sistema di storage a blocchi non è economico e non è una scelta d’elezione se si gestiscono tanti metadati.
Storage ad oggetti
Nello storage ad oggetti, invece, si parla di informazioni memorizzate sempre con i metadati corrispondenti. In questo caso i file vengono divisi in unità discrete, in punti diversi dell’hardware, rispetto al quale l’agnosticismo è completo, per cui alcuni vendor per esempio parlano di “struttura piatta”, con le informazioni sull’ubicazione della memoria che li contiene che è del tutto marginale.
Queste unità, gli “oggetti” risiedono né in directory né in blocchi. I volumi, nello storage ad oggetti sono singoli repository indipendenti, con un identificativo univoco per identificare l’oggetto e i metadati che descrivono una serie di caratteristiche supplementari vitali anche per il corretto trattamento del dato (quindi per esempio le limitazioni di accesso etc.etc.).
Con object storage si beneficia della massima flessibilità per quanto riguarda la possibilità di adattarsi a grandi quantità di dati e gli oggetti sono recuperabili in velocità perché contengono tutte le informazioni per il loro trattamento. Inoltre gli oggetti sono l’ideale per ospitare i dati non strutturati.
Per contro, non è questa l’architettura migliore per salvare e trattare dati che sono soggetti a tante modifiche, perché ogni volta che viene modificato un dato viene generato un altro oggetto, che è di suo un processo più “lento” rispetto alla generazione di un nuovo file. Anche per questo non è lo storage ad oggetti un sistema adeguato per trattare i dati dei DB. C’è ancora un vantaggio da sottolineare, però, è questo il tipo di memorizzazione più sicuro rispetto all’obsolescenza hardware.
File e object storage le differenze
In un confronto estremo possiamo mettere a fuoco le differenze tra un sistema di file storage e object storage sottolineando queste caratteristiche. Per quanto riguarda le performance: lo storage ad oggetti risolve le problematiche tipiche di quando si deve gestire una grande quantità di dati e sono richiesti throughput importanti, mentre il file storage è il sistema più vantaggioso nel caso di file di dimensioni ridotte, con l’indicazione dell’applicazione che lo aprirà. Per quanto riguarda la collocazione geografica dell’informazione, con object storage i dati possono essere memorizzati in modo trasversale anche su region multiple, mentre nel file storage sono memorizzati prevalentemente in locale.
Inoltre mentre con lo storage ad oggetti è possibile scalare tendenzialmente fino a infinito e comunque nell’ordine degli exabyte, i limiti operativi del file storage sono di pochi petabyte. Per quanto riguarda gli analytics, grazie all’utilizzo dei metadati, le informazioni nello storage ad oggetti permettono un’agile organizzazione delle informazioni e velocità nel recupero delle stesse. Invece, per quanto riguarda gli scenari di file storage, certo è possibile l’utilizzo dei metadati, ma in un set limitato.

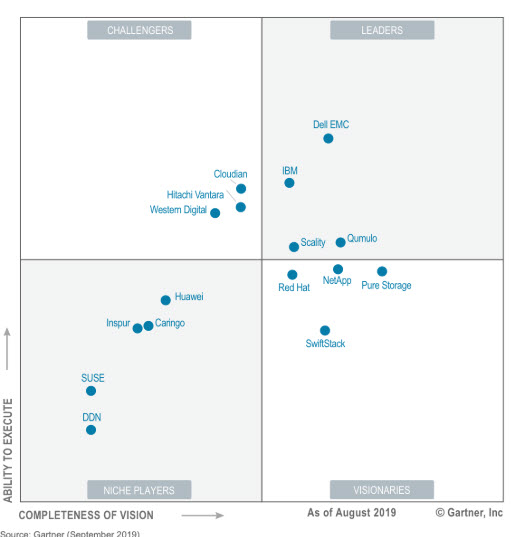
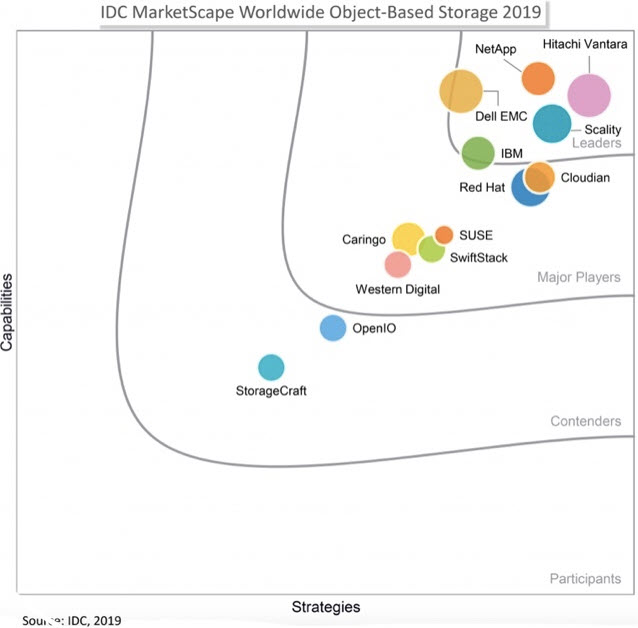
E’ opportuno scegliere lo storage ad oggetti, negli ambiti della data protection, quando si dispone di archivi di dati media importante (quindi anche per gli scenari healthcare – per esempio con i sistemi Pacs – e per la videosorveglianza), in tutti i casi in cui si sceglie di erogare un servizio storage in cloud. Per esempio nel primo scenario di utilizzo lo storage ad oggetti rappresenta una delle possibilità di scelta offerte da Rubrik, Veritas, Veeam, Commvault, Cloudian, così come nell’offerta SaaS. Su tutti è impossibile non citare l’offerta di Amazon S3.
© RIPRODUZIONE RISERVATA






